![]()
 |
 |
||
 |
 |
 |
The Chaotic processes analyzer (CPA) project.
(c) Alexey A. Mekler, 2006
Here one can download software for calculating of correlation dimension of reconstructed attractor of chaotic time series.
Software is based on algorithms, proposed in TISEAN project. The main issue of this software is automation of TISEAN algorithms.
So, two archives must be downloaded.
First – from TISEAN homepage (or directly from here). It must be unpacked and the following files must be extracted from subdirectory .\exe_files\:
- d2.exe
- c2t.exe
- av-d2.exe
- mutual.exe
- stp.exe
- rescale.exe
- cygwin.dll
Second – archive that contains distributive with all additional files can be downloaded here.
This archive contains a set of programs, that make it possible calculating of correlation dimension of reconstructed attractor in automatic mode:
· dynamic link library, that contains all additional procedures (d2dlib.dll);
· main program, that organizes calculation process (d2work.exe);
· ini-file, that contains parameters for calculations (d2.ini);
· a graphic interface program, which helps to make proper ini-file (D2_ini_writer.exe);
· several files with sample time series (Henon map, Lorentz, Ikeda, EEG).
There is a commercial version of this software, which exists as a part of electroencephalographic complex “WinEEG” (Mitsar Ltd., St.-Petersburg).
Mathematical basics, implemented here, are stated in help file for it (section “technical notes”). This help file can be downloaded here. Also, one can find proper citations in the corresponding section of this file. Information, provided in other sections of this help file does not concern this freeware.
In order to perform calculations it is necessary to do the following:
1. Launch program D2_ini_writer.exe and set desirable parameters for calculations:
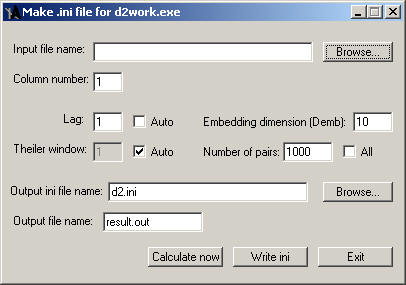
Here are comments on some fields.
"Input file name" – input file must be ASCII – a column of numbers, preferably with extension .txt or .dat.
"Column number" – input file may contain several time series – columns; here one can choose number of column. NB – column number must not exceed total number of columns.
"Number of pairs" – program d2.exe from TISEAN project can perform fast correlation integral calculations. It takes in account not all possible pairs of points, but only some of them (by default - 1000), randomly chosen. For more details see TISEAN documentation. If the checkbox "all" is checked, counting of all possible pairs is performed.
"Output ini-file name" and "output file name" – in first case – name of ini file, to which parameters of calculations are to be stored; in second – name of file with results of calculations. Ini-file must have extension ".ini" and is recommended (but not mandatory) to be set as d2.ini.
2. After the parameters of calculations are set, calculations may be started immediately by pressing button "Calculate now". It will store parameters and launch main program d2work.exe. If button "Write ini" will be pressed, ini file will be formed.
3. After ini file is made, main program may be launched (of course, if it was not launched by pressing "Calculate now"). The result will be stored in previously specified file with the following format:
#m= 3
2.963583
0.029028
2.910031
3.001503
In the first line – embedding dimension;
second – average value of correlation dimension in the scaling region;
third – variances of value of correlation dimension in the scaling region;
forth and fifth – max and min valuee of correlation dimension in the scaling region respectively;
This file contain results of calculations, made for all values of embedding dimension from 1 to specified value.
4. Some parameters for d2work.exe may be set in command prompt:
d2work.exe -iini-file -oout_file in_file
Here:
ini_file – name of ini-file, that contains parameters for calculations;
out_file – name of file, to which results will be stored;
in_file – name of file with input data.
Priorities of setting the parameters are the following:
first – from command prompt; those, which were not specified in command prompt – from ini file. If any of parameters is not specified neither in command prompt nor in ini-file, the following defaults will be set:
input data file – data.dat;
column number – 1;
lag – unit (1);
embedding dimension – 10;
Theiler window – automatic (see documentation);
number of pairs to be counted – 1000;
ini-file name – d2.ini;
output file name – res.out
If any error is occurred during calculation process, report is written to d2.log.
So, using this software, one can easy organize calculations for big number of data files.